.pull-left[ <br><br><br> <br><br><br> # Why I love <br><br><br> <br><br><br> <i class="fas fa-envelope "></i> chris.mainey@uhb.nhs.uk <i class="fas fa-globe "></i> [mainard.co.uk](https://www.mainard.co.uk) <i class="fab fa-github "></i> [github.com/chrismainey](https://github.com/chrismainey) <i class="fab fa-twitter "></i> [twitter.com/chrismainey](https://twitter.com/chrismainey) ] .pull-right[ <br><br><br> <br> ] --- # What is it? + Modern reworking of `data.frame` + Implemented in C for speed and portability + Using Low level paralellism via OpenMP + Supports keys, to physiscally order data in memory -- # Why? + `data.frame` is slow, `data.table` is fast: -- + Like, _reeeeeally fast_ : https://h2oai.github.io/db-benchmark/ -- + Pass by reference, not by value. -- + It uses minimal memory -- + Fast I/O functions: `fread` and `fwrite` --- # Synatx overview <br><br> 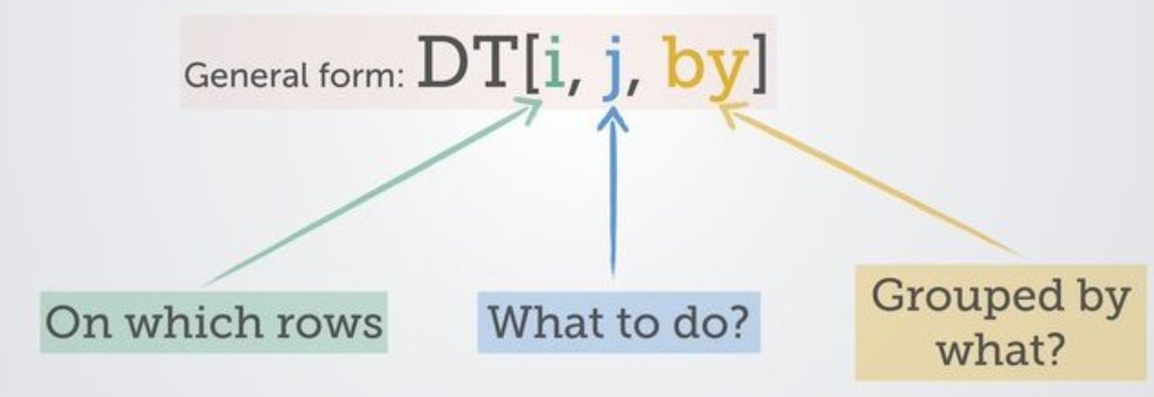 .footnote[ Image taken from `data.table` wiki, via Megan Stodel's excellent blog post: https://www.meganstodel.com/posts/data-table/ ] --- # Examples ```r library(NHSRdatasets) library(data.table) dt<-data.table(LOS_model, key = "Organisation") dt[Organisation == "Trust1", median(LOS)] ``` ``` ## [1] 5 ``` ```r dt[,.(Mean = mean(LOS), Median=median(LOS)), Organisation] ``` ``` ## Organisation Mean Median ## 1: Trust1 5.066667 5.0 ## 2: Trust2 4.233333 3.0 ## 3: Trust3 5.066667 4.5 ## 4: Trust4 4.866667 4.0 ## 5: Trust5 6.100000 4.5 ## 6: Trust6 4.900000 4.0 ## 7: Trust7 5.100000 4.0 ## 8: Trust8 4.700000 3.0 ## 9: Trust9 5.033333 4.0 ## 10: Trust10 4.300000 3.0 ```